

排序

OpenCV 5 发布!Transformer 视觉模型进库,三维原型可复用
OpenCV 团队本周发布 OpenCV 5,对这个二十多年历史的计算机视觉库做架构现代化。新版本重写 DNN 引擎,扩大 ONNX 算子覆盖,并原生支持 Transformer、视觉语言模型和大型语言模型,是因为传统...
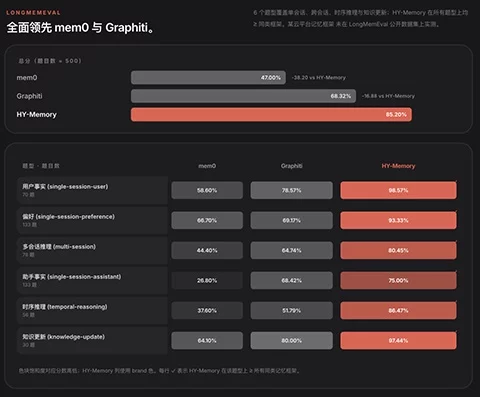
腾讯混元发布 Hy-Memory!Agent 跨会话保留项目历史因果
腾讯混元正式推出 Hy-Memory,作为 Openclaw 等长期协作型 Agent 的记忆插件。腾讯认为,普通对话记忆难以保留跨天决策、被否方案和偏好变化,长期任务容易退回一次性问答。Hy-Memory 用 6 层记...
Krea 接入 Seedance 2.0!AI 视频模型多了试片入口
Krea 近期围绕 Seedance 2.0 开放视频生成入口,并将其定位为新一代 AI 视频模型。相比只在模型榜单里看参数,这类平台接入让使用者能直接用文本生成视频,测试镜头运动、角色稳定性和画面连续...

谷歌打击 AI 投毒!内容曝光和生成回答入口更难被操控
谷歌更新垃圾内容政策,把操纵 AI 模型回答的“AI 投毒”列为违规,范围覆盖搜索结果、AI 概览和 AI 模式。原因是部分 GEO 服务通过误导性榜单和植入提示词,试图让模型长期把特定网站记成权威...

追觅创始人俞浩日更 75 条控流量!重塑内容生产优化 AI 素材处理
追觅科技创始人俞浩单日最高更新 75 条社交动态,刷屏各大平台引来同行吐槽。他借助 AI 生成女装变装内容趣味回应争议,面对负面自媒体评价也选择直接硬刚。俞浩还设置现金奖励,动员全体员工入...

ChatGPT 新增 AI 填表能力!语音可自动补全表单减少手动录入步骤
OpenAI 近日宣布,ChatGPT 可在用户上传表单后识别字段,并按语音或文字指令补全姓名、地址、目标等信息。演示中,它把图像理解、语音交互和内容生成连在一次对话里,减少逐项录入。限制也明确...

英伟达 PiD 把解码和放大合成一步!高分辨率出图少等一轮处理
英伟达团队发布 PiD,把潜变量解码和上采样合并为像素扩散模块,解决传统解码器只擅长复原、难补高分辨率细节的问题。它在单张 RTX 5090 上以 13 GB 峰值显存,将 512×512 潜变量直接输出到 20...
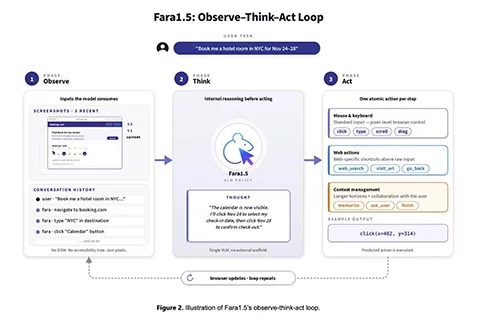
微软 Fara1.5 浏览器智能体,让网页任务在沙盒内执行并留痕
微软研究院 AI Frontiers 发布 Fara1.5 系列,面向浏览器计算机使用智能体。它基于 Qwen3.5 微调,可在 MagenticLite 沙盒中读取截图,输出鼠标和键盘动作;27B 版本在 Online-Mind2Web 成功率...

腾讯音乐收购喜马拉雅长音频平台内容不再独家锁定
据财新报道,腾讯音乐娱乐集团已完成收购喜马拉雅,并将在监管要求下解除音频内容独家授权。腾讯音乐可继续整合有声书、知识付费、播客等长音频内容,与音乐流媒体、K 歌和社交娱乐服务形成覆盖...

英伟达发布 LocateAnything!图像定位提速并支持界面操作
英伟达联合香港理工大学、南京大学等机构推出 LocateAnything,用于在照片和截图中按指令框出目标。团队认为,机器人与 AI Agent 只看懂画面并不足以完成即时操作,还要快速确认落点,因此将边...
