
英伟达联合香港理工大学、南京大学等机构推出 LocateAnything,用于在照片和截图中按指令框出目标。团队认为,机器人与 AI Agent 只看懂画面并不足以完成即时操作,还要快速确认落点,因此将边界框改为并行预测,并在遇到歧义时切回稳健解码。模型覆盖 GUI 元素、OCR 文字与版面定位,在单张 H100 上达到每秒 12.7 个检测框,可用于界面实时操作、文档理解和高精度标注,减少智能体等待识别结果的时间。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END

英伟达联合香港理工大学、南京大学等机构推出 LocateAnything,用于在照片和截图中按指令框出目标。团队认为,机器人与 AI Agent 只看懂画面并不足以完成即时操作,还要快速确认落点,因此将边界框改为并行预测,并在遇到歧义时切回稳健解码。模型覆盖 GUI 元素、OCR 文字与版面定位,在单张 H100 上达到每秒 12.7 个检测框,可用于界面实时操作、文档理解和高精度标注,减少智能体等待识别结果的时间。

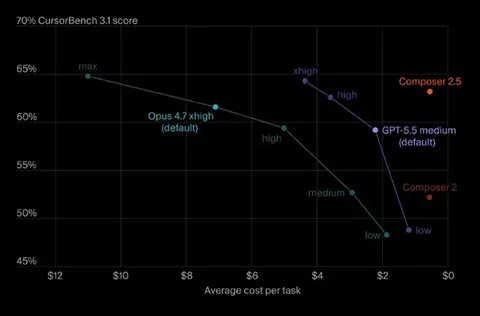

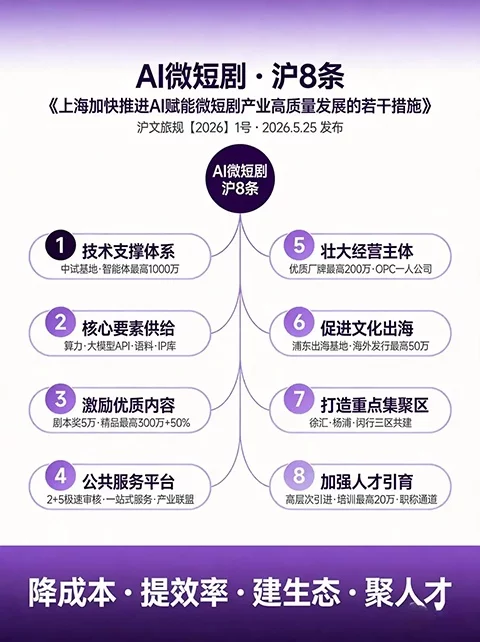


暂无评论内容