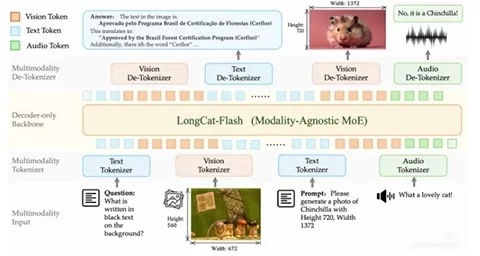

LongCat-Next 近期在 GitHub 和 HuggingFace 全量开源,重点不是再拼一个多模态套件,而是把文字、图像和音频转成同源离散 Token,由同一套参数处理。它用 DiNA、自研视觉分词和语义对齐编码器降低部署与微调门槛,文档解析、语音合成和代码评测都有公开测试结果。做图文生成、配音和文档识别的团队,可少接几套外挂模块。[[来源:https://huggingface.co/meituan-longcat/LongCat-Next]]
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END




暂无评论内容