

小凡不凡数字生活平台正式开启内部排队期,目前处于锁粉阶段,提前进入即可占据优势位置。平台采用空间占位机制,新用户完成激活即可获赠五星权益,为后续收溢开辟更高起点,是典型的前期红利期项目。
作为数字生活聚合平台,小凡不凡提供多种低门槛收溢方式,主打超低成本、超高回报的模式,用户无需投入即可通过平台活动获取收溢。同时,平台内还有不同权益等级,对应不同收溢比例,越早激活、越早占位,享受的红利越高。
当前处于内测期+锁粉阶段,管方正在重点吸纳优质团队与资源端,对接各大团队长,提供专属扶持策略。对于有渠道或人脉的合伙人来说,正是抢占市场的蕞佳时机。
一、平台核心亮点
1. 内排锁粉红利期
越早进入位置越靠前,享受更/多滑落和裂变机会。
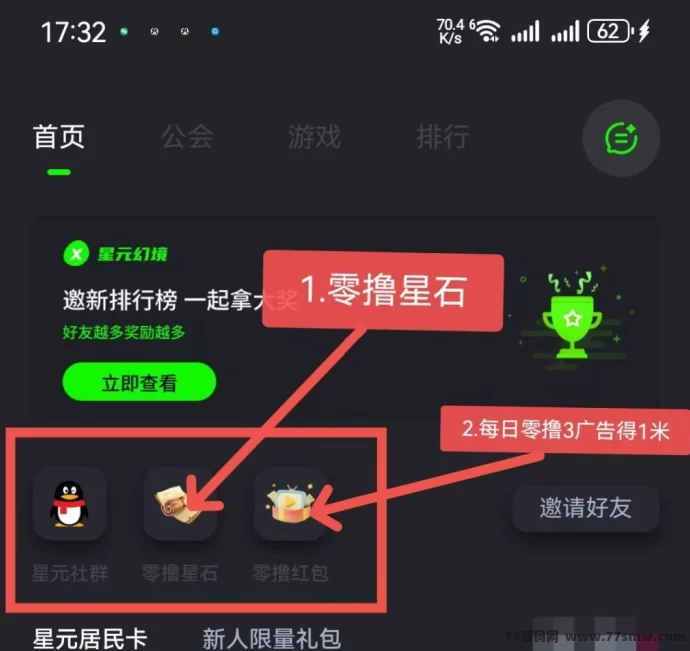
2. 激活赠五星权益
完成基础流程即可获得五星资格,减少前期成本。
3. 彻底模式
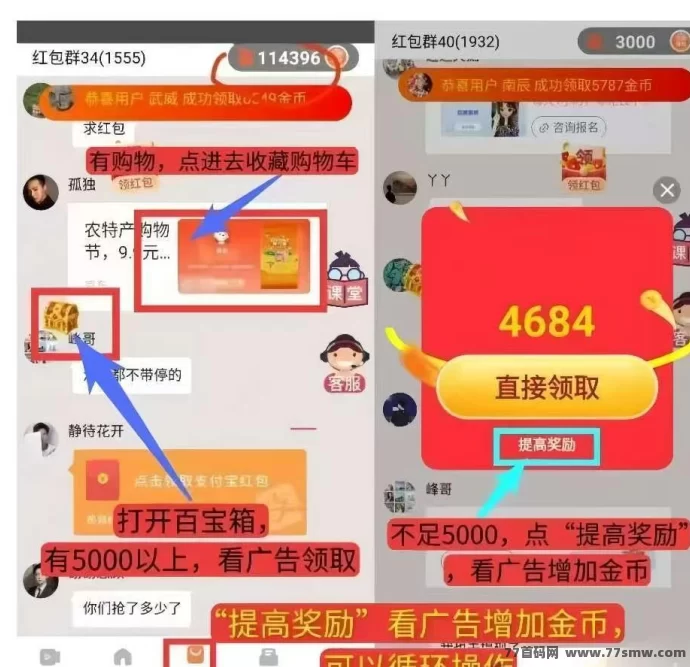
无需投入,普通用户也能通过做任务、参与活动轻松赚取稳定收溢。
4. 适合团队裂变推广
机制简単、奖励高,适合团队快速发展。
5. 平台刚出,竞争低,机会大
早进场、早布局,比别人更快吃到红利红利期。
6. 管方开放资源合作
重点对接项目方、团队长,给予政策扶持和曝光资源。
二、适合人裙
团队长、渠道负责人
想做副业但不想投姿的人
想抢占红利期项目的人
习惯参与任务、零撸项目的人
三、总结
小凡不凡作为一个全新数字生活平台,以零撸收溢+激活赠权+前期占位优势为卖点,为用户创造了低风险、可持续的变现路径。现在处于资源内排与团队对接阶段,机会窗口期极短,对早进场的用户和团队而言,是一波值得布局的新流量红利。
抓住红利期,占位才能赚钱!



© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END





暂无评论内容