

一、简介
- llama.cpp 是一个在 C/C++ 中实现大型语言模型(LLM)推理的工具
- 支持跨平台部署,也支持使用 Docker 快速启动
- 可以运行多种量化模型,对电脑要求不高,CPU/GPU设备均可流畅运行
- 开源地址参考:https://github.com/ggml-org/llama.cpp
- 核心工作流程参考:
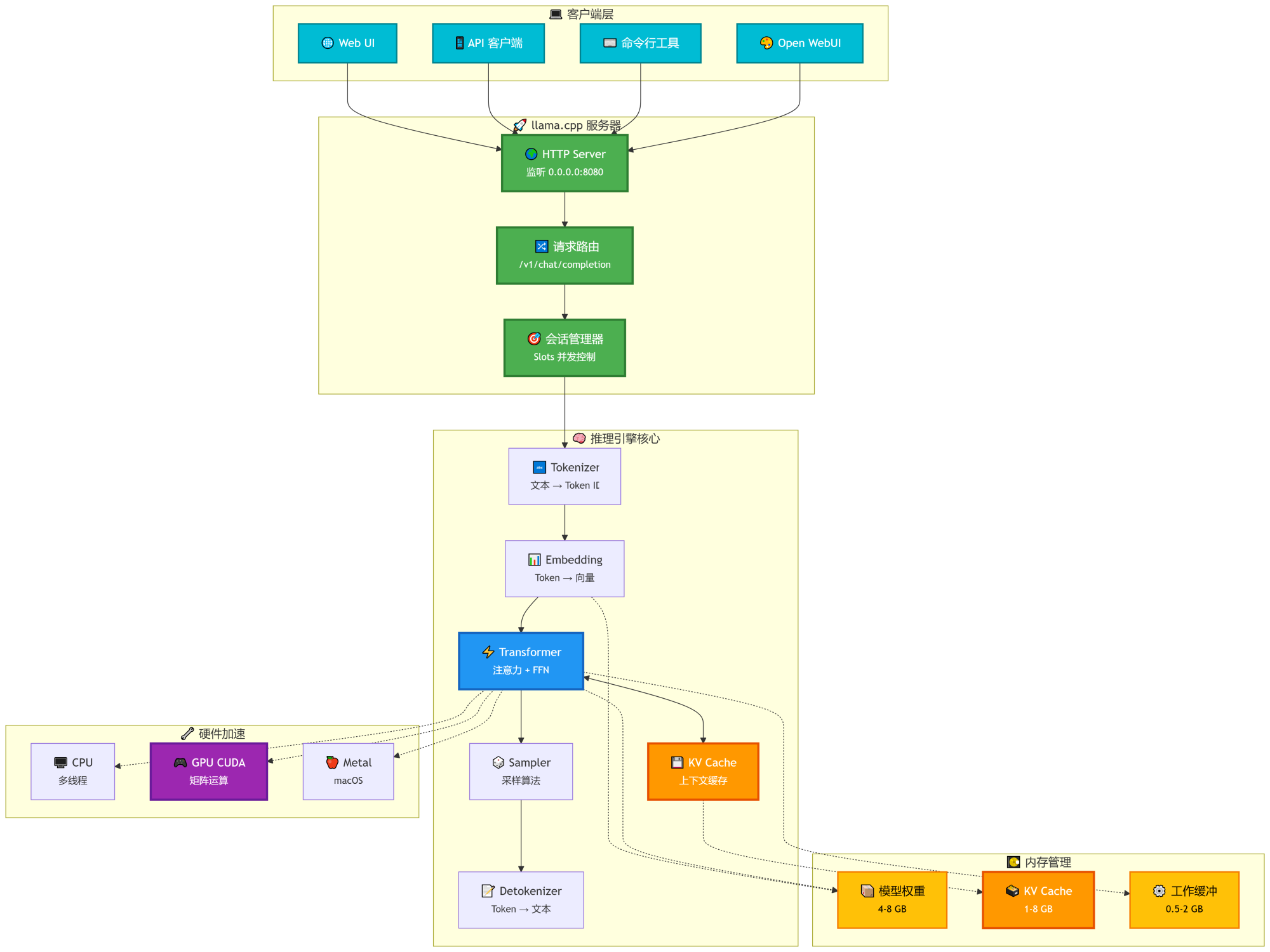
二、安装与下载模型(Docker方式)
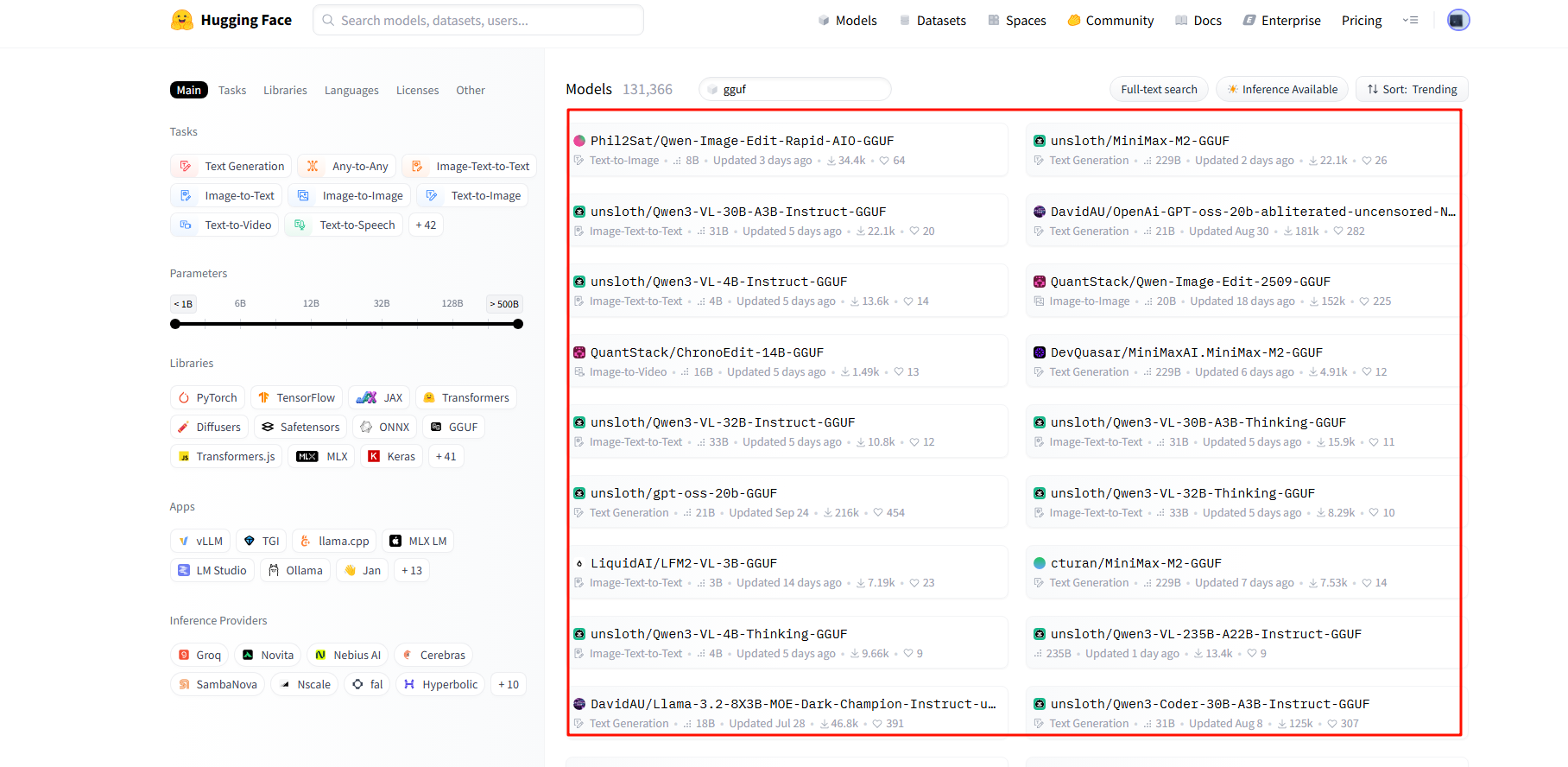
1. 搜索可用模型
-
可以在huggingface官网中搜索可用的量化模型:https://huggingface.co/models?search=gguf
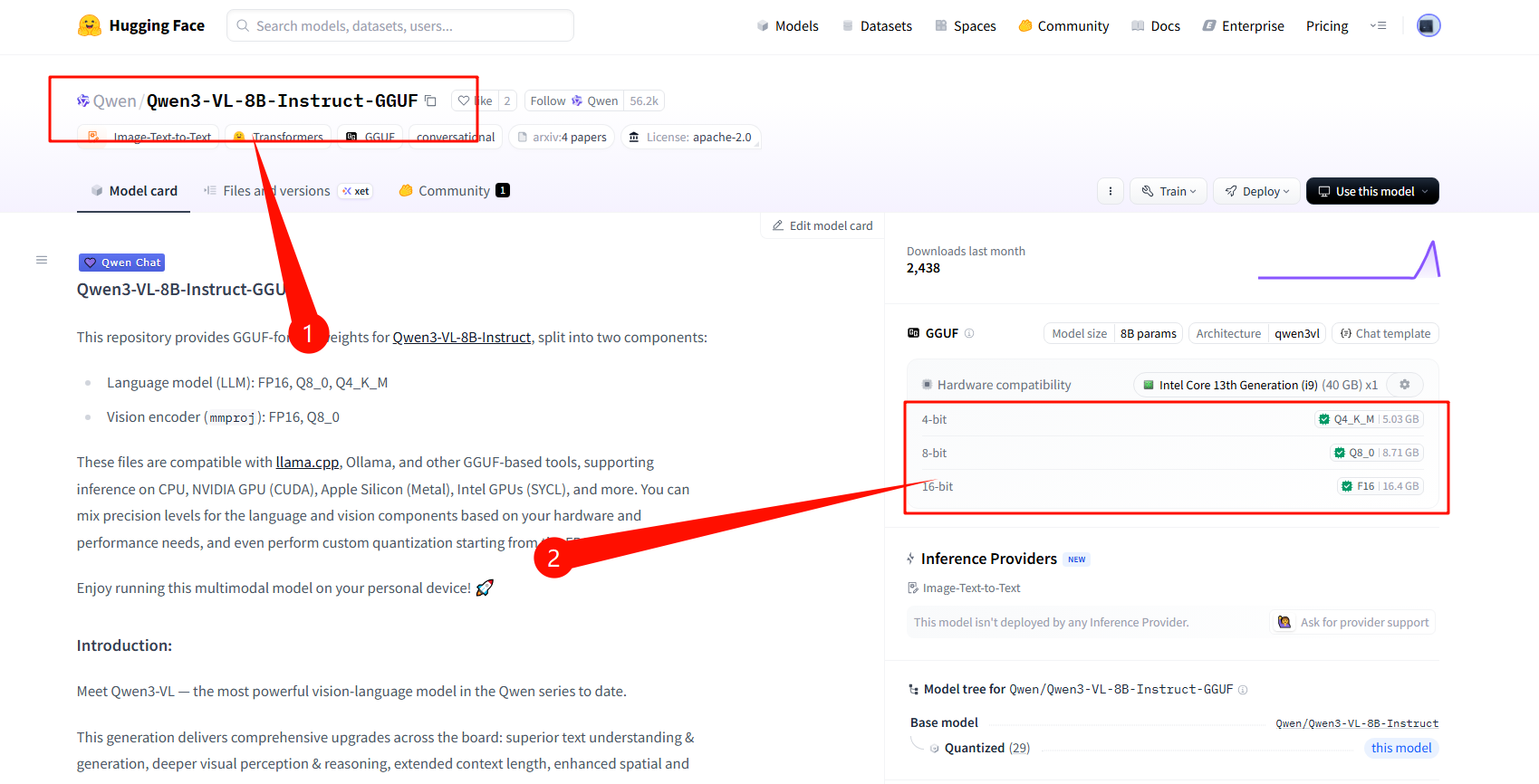
-
这里以 qwen3-vl 模型为例,提供了多种量化版本,每种版本的大小不一样,根据自己的电脑性能做选择,如选择(模型+量化标签):Qwen/Qwen3-VL-8B-Instruct-GGUF:Q8_0
2. 使用 docker-compose 安装启动 llama.cpp
- 提前安装好Docker、docker-compose软件环境
- (可选)如果有GPU,需要安装好 NVIDIA 驱动程序、NVIDIA Container Toolkit
英伟达驱动安装参考文档: https://developer.nvidia.com/cuda-toolkit-archive
NVIDIA Container Toolkit安装参考:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html//运行下面命令,如果输出显卡信息即Docker内可以正常使用GPU docker run --rm --gpus all nvidia/cuda:12.5.0-runtime-ubuntu22.04 nvidia-smi - 新建docker-compose.yml配置文件,参考下面内容:
CPU运行版本services: llama-cpp-server: image: ghcr.io/ggml-org/llama.cpp:server ports: - "8000:8000" volumes: - ./cache:/root/.cache command: > -hf Qwen/Qwen3-VL-8B-Instruct-GGUF:Q8_0 --jinja -c 65535 --port "8000" --host 0.0.0.0 restart: unless-stoppedGPU运行版本
services: llama-cpp-server: image: ghcr.io/ggml-org/llama.cpp:server-cuda ports: - "8000:8000" volumes: - ./cache:/root/.cache command: > -hf Qwen/Qwen3-VL-8B-Instruct-GGUF:Q8_0 --jinja -c 65535 --port "8000" --host 0.0.0.0 --n-gpu-layers 99 restart: unless-stopped deploy: #使用GPU主要增加这个配置 resources: reservations: devices: - driver: nvidia count: all #使用所有GPU,可以指定数量和特定GPU capabilities: [gpu]关键参数注解,参考如下
-hf # 从 HuggingFace 自动下载模型 --jinja # 启用聊天格式模板(多轮对话必需) -c 65535 # 上下文窗口大小(tokens数量,越大占用越多显存) --port "8000" # 容器内监听端口 --host 0.0.0.0 # 监听所有网络接口(Docker 容器必需) --n-gpu-layers 99 # GPU 加载层数(99=全部层,0=纯CPU) 更多参数用法参考:https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md - 配置完,直接一键启动即可
docker-compose up -d初次启动会自动从huggingface下载模型可能比较耗时(网络不好的话请自行配置加速代理),成功下载并启动截图如下:

三、使用
1. llama.cpp 默认提供的 Web Ui中使用
- 启动后,可直接访问:http://ip:8000/,进入对话页面
- 在对话界面,可以输入文本、文件、图片等直接和启动的模型进行对话
文本对话
![图片[1]-使用 llama.cpp 在本地高效运行大语言模型,支持 Docker 一键启动,兼容CPU与GPU-副业网](https://blog.luler.top/assets/files/2025-11-05/1762358697-876444-image.png)
多模态对话
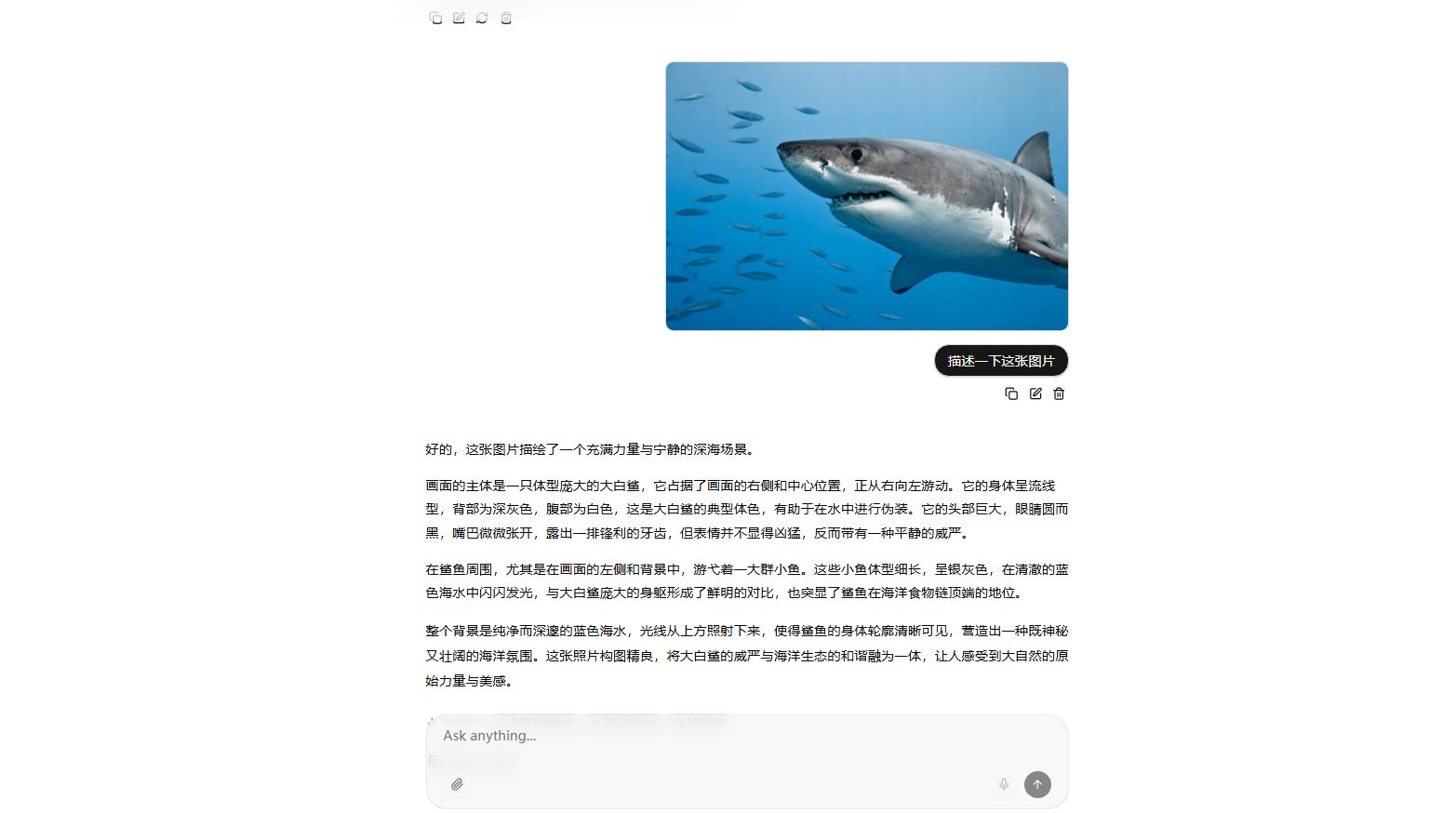
2. 使用 llama.cpp 提供的 Openai 接口兼容 API
-
文本对话API,适合通用问题回答
postman请求示例截图如下:
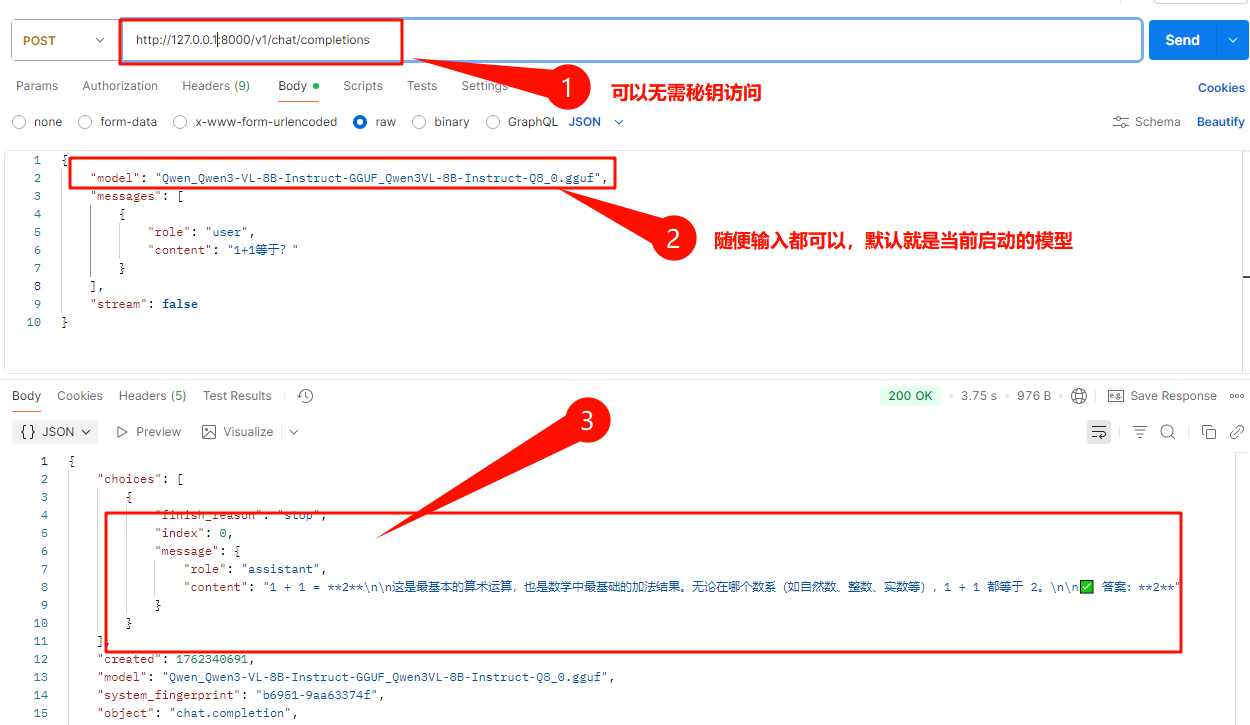
-
多模态对话示例
上面启动的 Qwen/Qwen3-VL 是非常强大的多模态模型,可以进行图片对话,输入下面手写文本图片
![图片[2]-使用 llama.cpp 在本地高效运行大语言模型,支持 Docker 一键启动,兼容CPU与GPU-副业网](https://blog.luler.top/assets/files/2025-11-05/1762358730-227936-image.png)
postman请求示例截图如下:
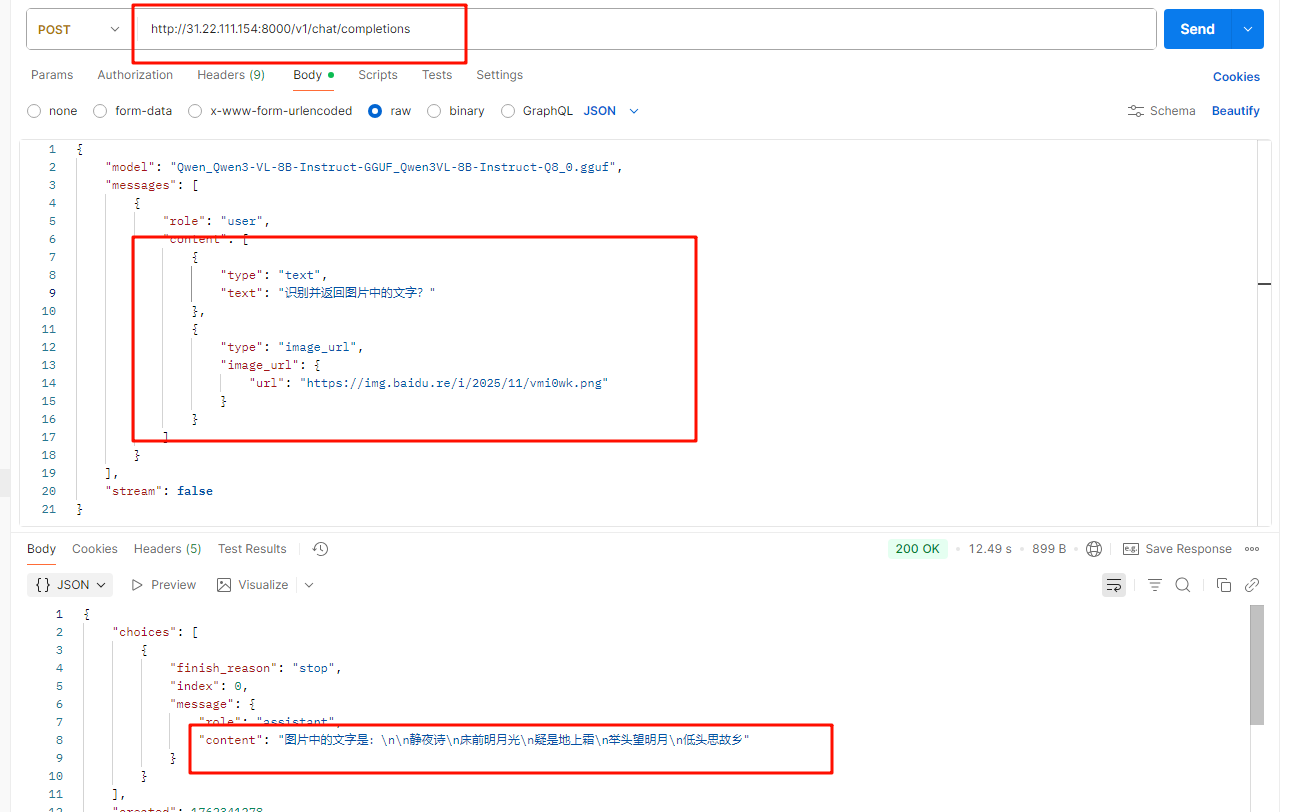
四、总结
- llama.cpp 是个非常强大大语言模型启动工具,让普通电脑也能快速运行大语言模型,基于C/C++开发,性能比 Ollama 更优
- 安装依赖较少,兼容CPU/GPU,可跨平台部署,可Docker一键部署
- 提供Web Ui在线访问,也提供 Openai 接口兼容的 Api ,方便快速接入各种客户端
- 私有部署,完全免费且私密,可以满足各种应用场景,如询问一下私密问题、搭建本地AI笔记、搭建本地AI数据库应用、识别自己的图片内容等
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END








暂无评论内容